Modul 5
Security Operations II
Cel
Po tym module masz umieć przejść od „coś się stało” do uporządkowanego procesu analizy i reakcji. Celem nie jest tylko znajomość narzędzi, ale rozumienie:
- jakie dane zebrać
- które narzędzie pasuje do problemu
- kiedy alert jest tylko sygnałem, a kiedy incydentem
- jak ograniczyć skutki incydentu
- jak nie zniszczyć dowodów
- jak wrócić do normalnego działania
- jak wyciągnąć wnioski po incydencie.
Po module powinieneś umieć:
- odróżnić event, alert i incident
- wyjaśnić rolę Security Information and Event Management (SIEM)
- dobrać narzędzia: Data Loss Prevention (DLP), Endpoint Detection and Response (EDR), Extended Detection and Response (XDR), Network Access Control (NAC), File Integrity Monitoring (FIM), Intrusion Detection System (IDS), Intrusion Prevention System (IPS)
- wskazać właściwe źródło logów do dochodzenia
- opisać etapy incident response
- odróżnić containment, eradication i recovery
- wyjaśnić legal hold i chain of custody
- rozumieć threat hunting i root cause analysis
- rozpoznać, gdzie automatyzacja pomaga, a gdzie tworzy ryzyko.
Wprowadzenie
Security Operations to codzienna praca polegająca na obserwowaniu środowiska, wykrywaniu nieprawidłowości, analizowaniu zdarzeń i reagowaniu na incydenty. W poprzednim module była mowa o tym, jak zabezpieczać zasoby, podatności i tożsamości. Teraz skupiamy się na tym, jak wykryć, że coś odbiega od normy, jak to potwierdzić i jak odpowiedzieć.
Egzamin Security+ często opisuje sytuację operacyjną: SIEM wygenerował alert, użytkownik zgłosił podejrzaną wiadomość, EDR wykrył proces, firewall zablokował ruch, logi zniknęły, aplikacja zaczęła wysyłać dane na zewnątrz albo administrator musi zabezpieczyć dowody. W takich pytaniach ważne jest nie tylko „jakie narzędzie”, ale też kolejność działań.
Wyjaśnienie
1. Event, alert i incident
Problem
W środowisku organizacji każdego dnia powstają tysiące lub miliony zdarzeń. Nie każde zdarzenie jest problemem. Nie każdy alert jest incydentem. Jeśli analityk tego nie rozróżnia, organizacja albo reaguje przesadnie, albo ignoruje sygnały ostrzegawcze.
Wyjaśnienie od podstaw
Event, czyli zdarzenie, to pojedynczy fakt zapisany przez system. Przykład: logowanie użytkownika, uruchomienie procesu, zmiana pliku, zablokowane połączenie przez firewall.
Alert to sygnał wygenerowany przez regułę, narzędzie lub korelację zdarzeń. Alert oznacza: „to może wymagać sprawdzenia”.
Incident, czyli incydent, to potwierdzona lub wystarczająco prawdopodobna sytuacja naruszenia bezpieczeństwa, która wymaga formalnej reakcji.
Jak to działa krok po kroku
System zapisuje zdarzenie.
Narzędzie monitoringu analizuje zdarzenia.
Reguła wykrywa podejrzany wzorzec.
Powstaje alert.
Analityk sprawdza kontekst.
Jeśli ryzyko jest realne, alert zostaje eskalowany do incydentu.
Zespół uruchamia proces incident response.
Przykład praktyczny
Jedno nieudane logowanie użytkownika rano to zwykłe zdarzenie. Dziesiątki nieudanych logowań z różnych lokalizacji dla wielu kont mogą wygenerować alert. Jeżeli analiza pokaże, że atakujący uzyskał dostęp do konta, mamy incydent.
Przykład egzaminacyjny
Scenariusz
SIEM wygenerował alert o logowaniu z nietypowej lokalizacji. Użytkownik często korzysta z firmowego VPN. Co powinien zrobić analityk?
Najlepsza odpowiedź:
Zweryfikować kontekst przed klasyfikacją jako incydent.
Z czym nie mylić
Alert nie jest dowodem samym w sobie. Jest początkiem analizy. Incydent wymaga reakcji, dokumentacji i często eskalacji.
Typowe błędy
Najczęstszy błąd to automatyczne traktowanie alertu jako potwierdzonego włamania. Drugi błąd to ignorowanie alertów bez triage, czyli wstępnej oceny.
Definicja do zapamiętania
Event to fakt, alert to sygnał ostrzegawczy, a incident to sytuacja bezpieczeństwa wymagająca reakcji.
2. Monitoring i alerting
Problem
Bez monitoringu organizacja dowiaduje się o incydencie zbyt późno: od użytkownika, klienta, mediów albo atakującego. Monitoring pozwala szybciej zauważyć odchylenia od normy.
Wyjaśnienie od podstaw
Monitoring to obserwowanie systemów, aplikacji, infrastruktury, użytkowników i ruchu sieciowego. Oficjalne cele SY0-701 wskazują monitoring computing resources, log aggregation, alerting, scanning, reporting, archiving oraz alert response and remediation/validation jako elementy security alerting and monitoring.
Alerting to generowanie ostrzeżeń na podstawie reguł, progów, korelacji lub zachowania.
Alert tuning to dostrajanie alertów tak, aby ograniczyć fałszywe alarmy, ale nie zgubić ważnych sygnałów.
Jak to działa krok po kroku
Systemy generują logi.
Logi trafiają do centralnego miejsca.
Narzędzie koreluje zdarzenia.
Reguły wykrywają wzorce.
Alert trafia do analityka lub systemu ticketowego.
Analityk wykonuje triage.
Alert zostaje zamknięty jako false positive albo eskalowany.
Po analizie reguły mogą zostać dostrojone.
Przykład praktyczny
SIEM ma regułę: „wiele nieudanych logowań, potem udane logowanie z nietypowej lokalizacji”. To silniejszy sygnał niż samo jedno błędne hasło. Alert jest lepszy, bo opiera się na korelacji kilku zdarzeń.
Przykład egzaminacyjny
Scenariusz
Zespół SOC otrzymuje zbyt wiele alertów, z których większość okazuje się nieszkodliwa. Co powinien zrobić?
Najlepsza odpowiedź:
Wykonać alert tuning, poprawić progi, reguły i kontekst alertów.
Z czym nie mylić
Nie myl alert tuningu z wyłączeniem monitoringu. Celem nie jest cisza, tylko lepsza jakość sygnałów.
Typowe błędy
Częsty błąd to zbieranie logów bez ich analizy. Drugi błąd to logowanie wszystkiego bez retencji, priorytetów i kosztowej kontroli przechowywania.
Definicja do zapamiętania
Monitoring zbiera i analizuje sygnały ze środowiska, alerting wskazuje zdarzenia wymagające uwagi, a alert tuning poprawia jakość wykrywania.
3. SIEM
Problem
Logi są rozproszone: firewall ma własne logi, serwer własne, aplikacja własne, endpoint własne, chmura własne. Bez centralizacji trudno zobaczyć pełny obraz incydentu.
Wyjaśnienie od podstaw
Security Information and Event Management (SIEM) to system zbierający, normalizujący, korelujący i analizujący logi oraz zdarzenia z wielu źródeł. SIEM pomaga wykrywać wzorce, generować alerty, prowadzić dochodzenia i tworzyć raporty.
SIEM nie „rozwiązuje incydentów sam”. To platforma, która pomaga analitykom szybciej zauważyć i zrozumieć problem.
Jak to działa krok po kroku
Źródła danych wysyłają logi do SIEM.
SIEM normalizuje formaty.
SIEM koreluje zdarzenia.
Reguły i analityka wykrywają podejrzane wzorce.
Powstaje alert.
Analityk przegląda timeline, hosty, konta, adresy IP i zdarzenia powiązane.
Wynik trafia do procesu incident response.
Przykład praktyczny
Atakujący loguje się do konta użytkownika, potem próbuje uzyskać dostęp do panelu administratora, a następnie eksportuje dużą ilość danych. Pojedynczo te zdarzenia mogą wyglądać niejasno. SIEM może skorelować je w jedną historię: podejrzane logowanie → eskalacja → eksfiltracja.
Przykład egzaminacyjny
Scenariusz
Firma chce centralnie zbierać logi z firewalli, serwerów, aplikacji i endpointów oraz korelować zdarzenia. Co najlepiej pasuje?
Najlepsza odpowiedź:
SIEM.
Z czym nie mylić
SIEM nie jest tym samym co EDR. SIEM zbiera i koreluje dane z wielu źródeł. EDR koncentruje się na endpointach i ich zachowaniu.
Typowe błędy
Częsty błąd to wdrożenie SIEM bez planu źródeł danych. SIEM jest tak dobry, jak dane, które otrzymuje, reguły, które ma, i proces reakcji, który go wspiera.
Definicja do zapamiętania
SIEM centralizuje i koreluje zdarzenia bezpieczeństwa z wielu źródeł, aby wspierać wykrywanie, analizę, alertowanie i raportowanie.
4. Narzędzia operacyjne: DLP, EDR, XDR, NAC, FIM, UBA
Problem
Różne problemy wymagają różnych narzędzi. Nie każde narzędzie służy do blokowania malware. Nie każde narzędzie analizuje sieć. Nie każde narzędzie chroni dane. Security+ często sprawdza, czy umiesz dobrać narzędzie do scenariusza.
Wyjaśnienie od podstaw
Data Loss Prevention (DLP) wykrywa lub blokuje nieautoryzowane przesyłanie danych wrażliwych. Może działać na endpointach, poczcie, sieci lub w chmurze.
Endpoint Detection and Response (EDR) monitoruje endpointy, czyli stacje robocze i serwery, wykrywa podejrzane procesy, zmiany plików, zachowanie malware i pozwala reagować, np. izolować hosta.
Extended Detection and Response (XDR) rozszerza analizę poza endpointy, łącząc dane z wielu warstw, np. poczty, sieci, chmury i tożsamości.
Network Access Control (NAC) kontroluje, czy urządzenie może uzyskać dostęp do sieci. Może sprawdzać zgodność urządzenia z polityką.
File Integrity Monitoring (FIM) wykrywa zmiany w ważnych plikach, np. plikach systemowych, konfiguracyjnych lub aplikacyjnych.
User Behavior Analytics (UBA) analizuje zachowanie użytkowników i szuka odchyleń od normy, np. nietypowych godzin logowania, masowego pobierania plików lub nietypowego dostępu.
Cele SY0-701 wymieniają m.in. DLP, NAC, EDR/XDR, user behavior analytics i file integrity monitoring wśród możliwości bezpieczeństwa przedsiębiorstwa.
Jak to działa krok po kroku
Identyfikujesz problem.
Sprawdzasz, czy dotyczy danych, endpointa, sieci, plików czy zachowania użytkownika.
Dobierasz narzędzie.
Ustawiasz polityki i alerty.
Monitorujesz wyniki.
Reagujesz na alerty.
Dostrajanie zmniejsza false positives i false negatives.
Przykład praktyczny
Pracownik próbuje wysłać plik z numerami PESEL na prywatny adres e-mail. DLP może wykryć wzorzec danych osobowych i zablokować wiadomość albo wygenerować alert.
Inny przykład: laptop zaczyna uruchamiać podejrzany proces i łączyć się z nieznaną domeną. EDR może pokazać drzewo procesów, hash pliku, użytkownika, połączenia sieciowe i pozwolić na izolację hosta.
Przykład egzaminacyjny
Scenariusz
Organizacja chce wykrywać nieautoryzowane zmiany w plikach konfiguracyjnych krytycznego serwera. Co najlepiej pasuje?
Najlepsza odpowiedź:
File Integrity Monitoring.
Z czym nie mylić
Nie myl DLP z backupem. DLP wykrywa lub blokuje wyciek danych. Backup pomaga odtworzyć dane. Nie myl NAC z VPN — NAC kontroluje dopuszczenie urządzenia do sieci, VPN tworzy tunel dostępu.
Typowe błędy
Częsty błąd to wdrożenie DLP bez klasyfikacji danych. Narzędzie musi wiedzieć, co jest wrażliwe. Drugi błąd to ignorowanie privacy i legalności przy monitorowaniu użytkowników.
Definicja do zapamiętania
DLP chroni dane przed nieuprawnionym wypływem, EDR/XDR wykrywa i wspiera reakcję na zagrożenia, NAC kontroluje dostęp urządzeń do sieci, FIM wykrywa zmiany plików, a UBA analizuje zachowanie użytkowników.
5. Firewall, IDS/IPS, web filtering, DNS filtering i email security
Problem
Ataki przechodzą różnymi drogami: przez sieć, pocztę, strony internetowe, DNS, aplikacje i endpointy. Jedna kontrola nie wystarcza. Trzeba rozumieć, gdzie dana kontrola działa najlepiej.
Wyjaśnienie od podstaw
Firewall kontroluje ruch na podstawie reguł, adresów, portów, protokołów, aplikacji lub kontekstu.
IDS wykrywa podejrzany ruch i alarmuje. IPS może aktywnie blokować.
Web filtering kontroluje dostęp do stron internetowych przez kategorie, reputację, reguły i skanowanie adresów URL.
DNS filtering blokuje zapytania do znanych złośliwych lub niepożądanych domen.
Email security chroni pocztę przez bramki, filtrowanie, reputację, sandboxing, reguły antyphishingowe oraz mechanizmy SPF, DKIM i DMARC. W celach SY0-701 email security obejmuje m.in. DMARC, DKIM, SPF i gateway.
Jak to działa krok po kroku
Ruch lub wiadomość trafia do organizacji.
Kontrola sprawdza źródło, cel, reputację, treść lub wzorzec.
Ruch jest dopuszczony, zablokowany, oznaczony albo przekazany dalej.
Zdarzenie jest logowane.
Alert trafia do analizy, jeśli spełnia warunki.
Przykład praktyczny
Użytkownik klika link z phishingu. Web filter może zablokować stronę. DNS filtering może zablokować rozwiązanie domeny. Email security mogło wcześniej oznaczyć wiadomość jako podejrzaną. EDR może wykryć skutki na endpointcie, jeśli użytkownik pobierze plik.
Przykład egzaminacyjny
Scenariusz
Firma chce ograniczyć skuteczność phishingu przez weryfikację, czy wiadomości rzeczywiście pochodzą z autoryzowanych serwerów domeny nadawcy. Które mechanizmy są właściwe?
Najlepsza odpowiedź:
SPF, DKIM i DMARC.
Z czym nie mylić
Nie myl DNS filtering z web filtering. DNS filtering działa na poziomie zapytań nazw domenowych. Web filtering analizuje dostęp do treści WWW, adresy URL, kategorie i reputację.
Typowe błędy
Częsty błąd to traktowanie filtra poczty jako pełnej ochrony przed phishingiem. Potrzebne są też MFA, szkolenia, raportowanie podejrzanych wiadomości, analiza logów i procedura reakcji.
Definicja do zapamiętania
Kontrole sieciowe, webowe, DNS i pocztowe ograniczają różne ścieżki ataku, dlatego powinny działać warstwowo i dostarczać logi do analizy.
6. NetFlow, SNMP traps i packet captures
Problem
Nie każdy problem widać w logach aplikacji. Czasem trzeba zobaczyć wzorce ruchu sieciowego: kto z kim rozmawia, ile danych przesyła, kiedy i jakim protokołem.
Wyjaśnienie od podstaw
NetFlow dostarcza metadane o przepływach sieciowych: źródło, cel, porty, protokół, ilość danych i czas. Zwykle nie pokazuje pełnej treści pakietów.
Simple Network Management Protocol (SNMP) traps to powiadomienia wysyłane przez urządzenia sieciowe, np. o awarii interfejsu, zmianie stanu lub przekroczeniu progu.
Packet capture to przechwycenie pakietów sieciowych do szczegółowej analizy. Jest bardziej szczegółowe niż NetFlow, ale generuje większą ilość danych i może zawierać wrażliwe informacje.
Jak to działa krok po kroku
Administrator lub narzędzie zauważa problem.
NetFlow pokazuje, że host wysyła nietypowo dużo danych.
SNMP trap może wskazać problem z urządzeniem sieciowym.
Packet capture może posłużyć do głębszej analizy konkretnego ruchu.
Wyniki trafiają do dochodzenia.
Przykład praktyczny
Serwer zaczyna wysyłać dużą ilość danych do zewnętrznego adresu IP w nocy. NetFlow może szybko pokazać wolumen i kierunek ruchu. Packet capture może pomóc ustalić szczegóły transmisji, jeśli jest to legalne i zgodne z polityką.
Przykład egzaminacyjny
Scenariusz
Analityk chce szybko sprawdzić, który host wysłał największy wolumen danych na zewnątrz, bez analizy pełnej treści pakietów. Co najlepiej pasuje?
Najlepsza odpowiedź:
NetFlow.
Z czym nie mylić
NetFlow nie jest pełnym packet capture. Packet capture jest dokładniejsze, ale cięższe operacyjnie i bardziej wrażliwe prywatnościowo.
Typowe błędy
Częsty błąd to zbieranie packet captures bez jasno określonego celu, retencji i kontroli dostępu. Takie dane mogą zawierać informacje poufne.
Definicja do zapamiętania
NetFlow pokazuje metadane przepływów, SNMP traps zgłaszają zdarzenia urządzeń, a packet capture umożliwia szczegółową analizę pakietów.
7. Incident response
Problem
Gdy dochodzi do incydentu, chaotyczne działania mogą pogorszyć sytuację: usunąć dowody, rozprzestrzenić malware, przedłużyć przestój albo narazić firmę na błędy prawne. Potrzebny jest proces.
Wyjaśnienie od podstaw
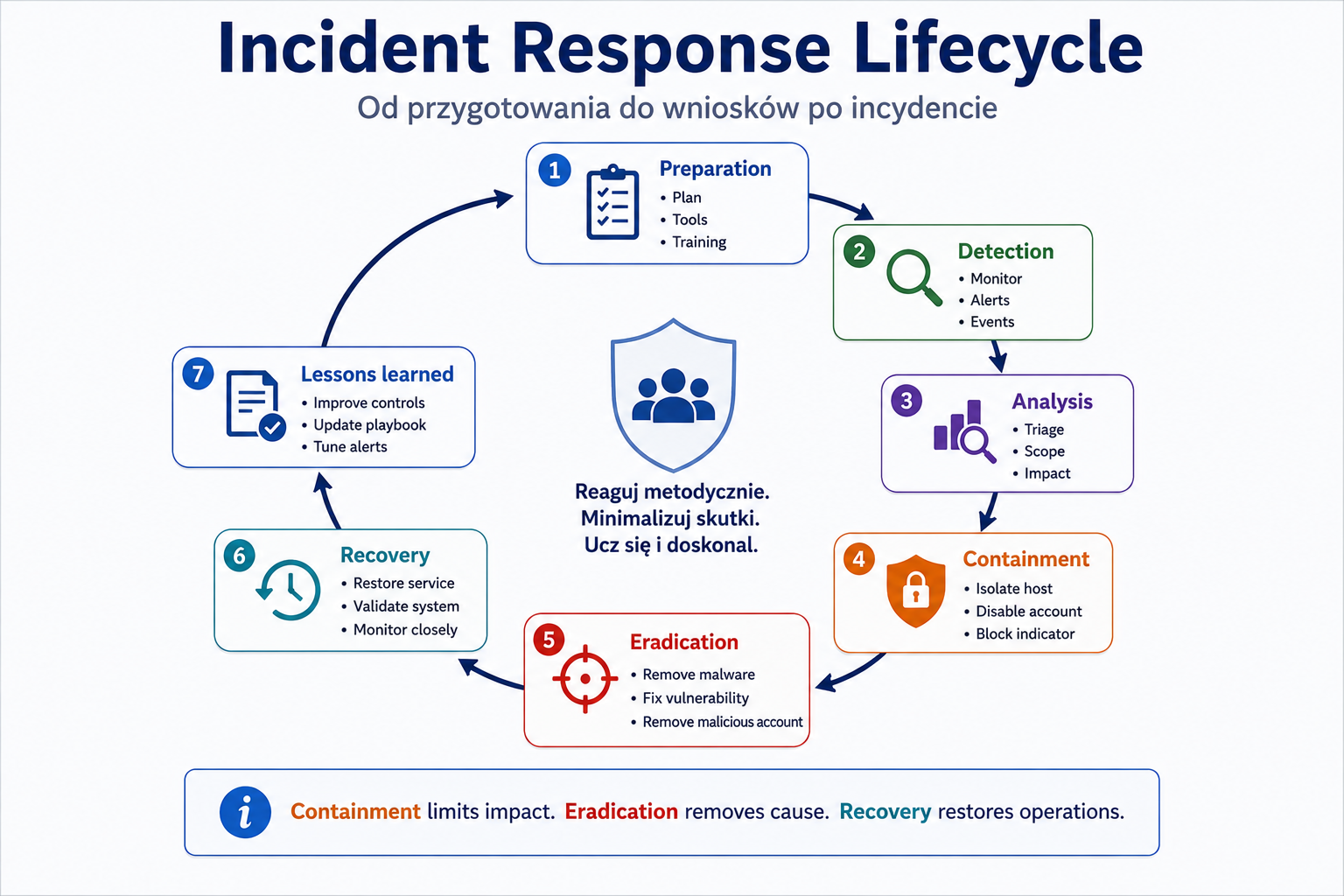
Incident response to uporządkowany proces reagowania na incydenty bezpieczeństwa. Oficjalne cele SY0-701 wskazują etapy: preparation, detection, analysis, containment, eradication, recovery oraz lessons learned.
Jak to działa krok po kroku
Preparation
Organizacja przygotowuje ludzi, narzędzia, procedury, kontakty, playbooki, backupy i uprawnienia.
Detection
Incydent jest wykrywany przez alert, użytkownika, EDR, SIEM, firewall, DLP lub inne źródło.
Analysis
Zespół ustala, co się stało, jakie zasoby są dotknięte, jaki jest zasięg i priorytet.
Containment
Zespół ogranicza skutki, np. izoluje hosta, blokuje konto, odcina segment, zatrzymuje wyciek.
Eradication
Zespół usuwa przyczynę, np. malware, podatność, błędną konfigurację, złośliwe konto.
Recovery
Systemy wracają do działania w kontrolowany sposób.
Lessons learned
Organizacja dokumentuje wnioski i poprawia zabezpieczenia.
Przykład praktyczny
EDR wykrywa ransomware na laptopie. Najpierw trzeba ograniczyć skutki: izolować hosta, sprawdzić udziały sieciowe i konta. Potem usuwa się malware, zamyka wektor wejścia, odtwarza dane z backupu i dokumentuje wnioski.
Przykład egzaminacyjny
Scenariusz
Zespół wykrył zainfekowany komputer, który komunikuje się z domeną command and control. Co jest najlepszym pierwszym działaniem operacyjnym?
Najlepsza odpowiedź:
Containment, np. izolacja hosta od sieci.
Z czym nie mylić
Containment nie jest tym samym co eradication. Containment ogranicza skutki. Eradication usuwa przyczynę. Recovery przywraca działanie.
Typowe błędy
Częsty błąd to natychmiastowe usunięcie plików lub restart systemu przed zabezpieczeniem dowodów. Drugi błąd to pominięcie lessons learned.
Definicja do zapamiętania
Incident response to kontrolowany proces od przygotowania, przez wykrycie i analizę, po ograniczenie skutków, usunięcie przyczyny, odzyskanie działania i wnioski końcowe.
8. Threat hunting i root cause analysis
Problem
Nie wszystkie zagrożenia zostaną wykryte przez gotową regułę. Czasem organizacja musi aktywnie szukać śladów atakującego. Po incydencie musi też ustalić przyczynę, żeby problem nie wrócił.
Wyjaśnienie od podstaw
Threat hunting to proaktywne szukanie oznak kompromitacji lub nieznanych zagrożeń. Zamiast czekać na alert, analityk stawia hipotezę i sprawdza dane.
Przykład hipotezy: „Atakujący mógł użyć legalnego narzędzia administracyjnego do lateral movement”.
Root cause analysis (RCA) to analiza przyczyny źródłowej. Odpowiada na pytanie: „dlaczego do tego doszło naprawdę?”. Przyczyną może być brak MFA, podatna aplikacja, nadmierne uprawnienia, brak segmentacji, błędna konfiguracja albo luka w procesie.
Jak to działa krok po kroku
Threat hunting:
- Formułujesz hipotezę.
- Wybierasz źródła danych.
- Szukasz wzorców.
- Weryfikujesz wyniki.
- Tworzysz detekcję lub poprawiasz kontrolę.
Root cause analysis:
- Opisujesz incydent.
- Ustalasz bezpośrednią przyczynę.
- Szukasz przyczyny systemowej.
- Określasz działania naprawcze.
- Sprawdzasz, czy problem nie wróci.
- Przykład praktyczny
Incydent: przejęto konto użytkownika. Bezpośrednia przyczyna: użytkownik podał hasło na fałszywej stronie. Przyczyna źródłowa: brak MFA dla zdalnego logowania i brak skutecznej ochrony phishingowej. RCA wskazuje, że samo zresetowanie hasła nie wystarczy.
Przykład egzaminacyjny
Scenariusz
Po usunięciu malware z systemu zespół chce ustalić, jak malware dostał się do środowiska i jakie kontrole trzeba poprawić. Co powinien wykonać?
Najlepsza odpowiedź:
Root cause analysis.
Z czym nie mylić
Threat hunting nie jest tym samym co zwykłe reagowanie na alert. Hunting jest proaktywny. RCA nie jest tym samym co szybkie usunięcie objawu.
Typowe błędy
Częsty błąd to zakończenie pracy po usunięciu malware. Bez RCA organizacja może zostać zainfekowana ponownie tą samą drogą.
Definicja do zapamiętania
Threat hunting aktywnie szuka ukrytych zagrożeń, a root cause analysis ustala przyczynę źródłową incydentu, aby zapobiec powtórzeniu.
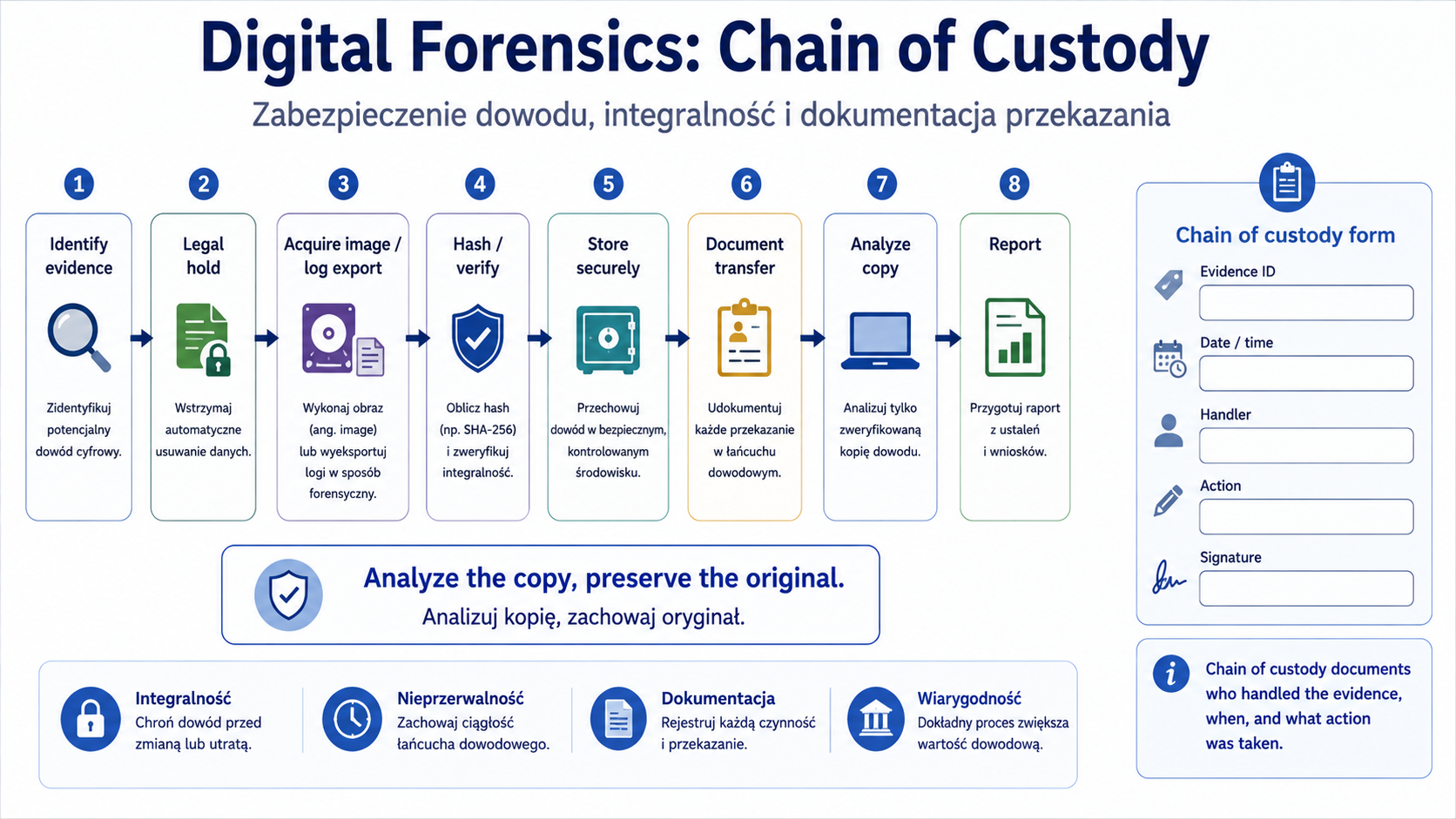
9. Digital forensics, legal hold i chain of custody
Problem
Niektóre incydenty wymagają dowodów, które mogą zostać użyte w postępowaniu prawnym, audycie lub dochodzeniu. Jeśli dowody zostaną źle zebrane, zmienione lub nieudokumentowane, mogą stracić wartość.
Wyjaśnienie od podstaw
Digital forensics to proces zabezpieczania, pozyskiwania, analizowania i raportowania dowodów cyfrowych.
Oficjalne cele SY0-701 obejmują legal hold, chain of custody, acquisition, reporting, preservation i e-discovery.
Legal hold oznacza obowiązek zachowania danych, które mogą być istotne dla sprawy prawnej lub dochodzenia.
Chain of custody to dokumentacja pokazująca, kto miał dostęp do dowodu, kiedy, gdzie, w jakim celu i co z nim zrobił.
Acquisition to pozyskanie dowodu, np. obrazu dysku, pamięci, logów lub danych z systemu.
Preservation to zachowanie dowodu w stanie możliwie niezmienionym.
E-discovery dotyczy identyfikowania i przekazywania informacji elektronicznych w kontekście prawnym.
Jak to działa krok po kroku
Organizacja identyfikuje potencjalny dowód.
W razie potrzeby uruchamia legal hold.
Dowód jest zabezpieczany.
Tworzona jest kopia lub obraz zgodnie z procedurą.
Każde przekazanie dowodu jest dokumentowane.
Analiza odbywa się na kopii, nie na oryginale, jeśli to możliwe.
Wyniki są raportowane.
Przykład praktyczny
Podejrzewa się, że pracownik wykradł dane przed odejściem. Organizacja zabezpiecza laptop, logi poczty, logi dostępu do plików i historię transferów. Każdy dowód jest opisany, zaplombowany lub logicznie zabezpieczony, a dostęp do niego jest dokumentowany.
Przykład egzaminacyjny
Scenariusz
Analityk zabezpiecza laptop jako dowód. Musi dokumentować każdą osobę, która miała dostęp do urządzenia. Jak nazywa się ten wymóg?
Najlepsza odpowiedź:
Chain of custody.
Z czym nie mylić
Nie myl forensics ze zwykłym troubleshootingiem. Troubleshooting ma szybko naprawić problem. Forensics ma zachować wartość dowodową i ustalić fakty.
Typowe błędy
Częsty błąd to analiza bezpośrednio na oryginalnym nośniku. Drugi błąd to brak dokumentacji, kto i kiedy miał dostęp do dowodu.
Definicja do zapamiętania
Digital forensics zabezpiecza i analizuje dowody cyfrowe, legal hold nakazuje ich zachowanie, a chain of custody dokumentuje ich kontrolę i przekazywanie.
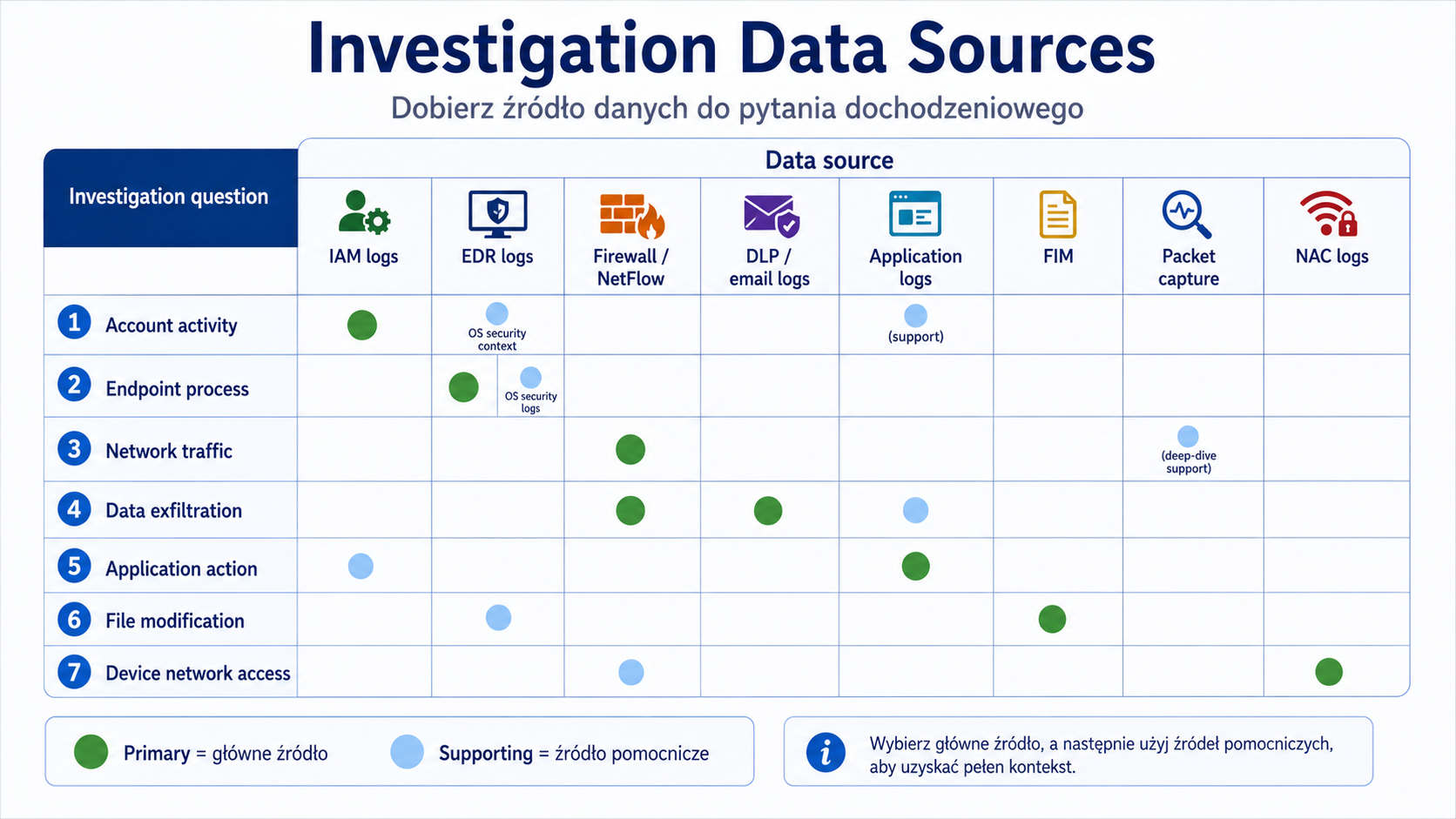
10. Źródła danych w dochodzeniu
Problem
Podczas incydentu trzeba wiedzieć, gdzie szukać dowodów. Inne źródło pokaże ruch sieciowy, inne proces na endpointcie, inne błąd aplikacji, a jeszcze inne zmianę uprawnień.
Wyjaśnienie od podstaw
Oficjalne cele SY0-701 wymieniają log data i data sources, m.in. firewall logs, application logs, endpoint logs, OS-specific security logs, IPS/IDS logs, network logs, metadata, vulnerability scans, automated reports, dashboards i packet captures.
Najważniejsze źródła:
| Źródło | Do czego służy |
|---|---|
| Firewall logs | Sprawdzenie dozwolonego i zablokowanego ruchu. |
| Application logs | Analiza błędów aplikacji, logowań, zapytań i operacji biznesowych. |
| Endpoint logs | Procesy, pliki, działania użytkownika, malware. |
| OS security logs | Logowania, zmiany kont, uprawnienia, zdarzenia systemowe. |
| IDS/IPS logs | Detekcja wzorców podejrzanego ruchu. |
| Network logs | Łączność, przepływy, aktywność sieciowa. |
| Metadata | Dane o danych, np. czas, autor, rozmiar, źródło. |
| Vulnerability scans | Informacje o znanych podatnościach. |
| Packet captures | Szczegółowa analiza pakietów. |
| Dashboards | Szybki widok trendów i stanu środowiska. |
Jak to działa krok po kroku
Określasz pytanie dochodzeniowe.
Wybierasz źródła danych.
Ustalasz zakres czasu.
Korelujesz użytkowników, hosty, adresy IP i procesy.
Tworzysz timeline.
Potwierdzasz lub odrzucasz hipotezę.
Dokumentujesz wynik.
Przykład praktyczny
Pytanie: „Czy dane zostały wyprowadzone z organizacji?”
Źródła: DLP, proxy logs, firewall logs, NetFlow, endpoint logs, application logs, cloud audit logs.
Pytanie: „Czy konto administratora zostało użyte nieprawidłowo?”
Źródła: IAM logs, OS security logs, PAM logs, SIEM, jump server logs.
Przykład egzaminacyjny
Scenariusz
Analityk chce ustalić, czy użytkownik wykonał masowy eksport danych z aplikacji. Które źródło będzie najtrafniejsze?
Najlepsza odpowiedź:
Application logs, ewentualnie uzupełnione DLP, firewall/proxy i endpoint logs.
Z czym nie mylić
Nie każde dochodzenie zaczyna się od packet capture. Często szybsze i bardziej trafne są logi aplikacji, IAM, endpointa lub firewall.
Typowe błędy
Częsty błąd to patrzenie tylko na jedno źródło danych. Incydenty zwykle wymagają korelacji wielu źródeł.
Definicja do zapamiętania
Źródło danych dobiera się do pytania dochodzeniowego: kto, co, kiedy, gdzie, jakim systemem i z jakim skutkiem.
11. Automatyzacja i orkiestracja
Problem
Ręczna obsługa każdego alertu jest wolna i podatna na błędy. Automatyzacja może skrócić czas reakcji, wymusić standardowe działania i zmniejszyć obciążenie zespołu. Jednocześnie źle zaprojektowana automatyzacja może masowo powielić błąd.
Wyjaśnienie od podstaw
Automation to automatyczne wykonanie zadania, np. utworzenie ticketu, dodanie adresu IP do listy blokady albo wyłączenie konta.
Orchestration to połączenie wielu automatycznych kroków w proces między systemami. Przykład: alert z SIEM tworzy ticket, EDR izoluje hosta, IAM blokuje konto, a zespół dostaje powiadomienie.
Cele SY0-701 wymieniają use cases automatyzacji, takie jak user provisioning, resource provisioning, guard rails, security groups, ticket creation, escalation, enabling/disabling services and access, continuous integration and testing oraz integracje przez Application Programming Interfaces (APIs). Wskazują też korzyści, m.in. oszczędność czasu, wymuszanie baseline’ów, standaryzację i szybszą reakcję, ale także ryzyka: złożoność, koszt, single point of failure, technical debt i supportability.
Jak to działa krok po kroku
Organizacja identyfikuje powtarzalny proces.
Definiuje warunki uruchomienia.
Określa kroki automatyczne.
Dodaje kontrolę bezpieczeństwa, np. zatwierdzenie dla ryzykownych działań.
Testuje automatyzację.
Wdraża ją stopniowo.
Monitoruje wyniki i błędy.
Przykład praktyczny
SIEM wykrywa podejrzane logowanie administratora z nietypowego kraju. Automatyzacja może utworzyć ticket, powiadomić SOC, wymusić reset sesji i poprosić o dodatkową weryfikację. W bardziej ryzykownych przypadkach może tymczasowo zablokować konto, ale takie działanie powinno być dobrze przetestowane.
Przykład egzaminacyjny
Scenariusz
Firma chce przyspieszyć reakcję na powtarzalne alerty i automatycznie tworzyć zgłoszenia oraz eskalować je do właściwego zespołu. Co najlepiej pasuje?
Najlepsza odpowiedź:
Automation/orchestration.
Z czym nie mylić
Nie myl automatyzacji z całkowitym zastąpieniem analityków. Automatyzacja dobrze obsługuje powtarzalne kroki, ale trudne decyzje nadal wymagają człowieka.
Typowe błędy
Częsty błąd to automatyczne blokowanie bez testów i wyjątków. Fałszywy alert może wtedy zablokować krytyczne konto lub usługę.
Definicja do zapamiętania
Automatyzacja wykonuje pojedyncze zadania, a orkiestracja łączy wiele kroków i systemów w spójny proces reakcji.
Kluczowe pojęcia
| Pojęcie | Znaczenie |
|---|---|
| Event | Pojedyncze zdarzenie zapisane przez system. |
| Alert | Ostrzeżenie wygenerowane przez regułę, narzędzie lub korelację. |
| Incident | Sytuacja bezpieczeństwa wymagająca reakcji. |
| Log aggregation | Centralne zbieranie logów. |
| Alert tuning | Dostrajanie reguł i progów alertów. |
| SIEM | System centralizacji, korelacji i analizy zdarzeń bezpieczeństwa. |
| DLP | Kontrola wykrywająca lub blokująca nieautoryzowany wypływ danych. |
| EDR | Narzędzie wykrywania i reakcji na endpointach. |
| XDR | Rozszerzona detekcja i reakcja z wielu źródeł. |
| NAC | Kontrola dostępu urządzeń do sieci. |
| FIM | Monitorowanie integralności plików. |
| UBA | Analiza zachowania użytkowników. |
| NetFlow | Metadane przepływów sieciowych. |
| SNMP traps | Powiadomienia urządzeń sieciowych o zdarzeniach. |
| Packet capture | Przechwycenie pakietów do szczegółowej analizy. |
| Incident response | Proces reagowania na incydenty bezpieczeństwa. |
| Containment | Ograniczenie skutków incydentu. |
| Eradication | Usunięcie przyczyny incydentu. |
| Recovery | Przywrócenie normalnego działania. |
| Lessons learned | Wnioski i poprawki po incydencie. |
| Threat hunting | Proaktywne szukanie śladów zagrożeń. |
| Root cause analysis | Analiza przyczyny źródłowej. |
| Legal hold | Obowiązek zachowania danych jako potencjalnych dowodów. |
| Chain of custody | Dokumentowanie kontroli nad dowodem. |
| Acquisition | Pozyskanie dowodu cyfrowego. |
| Preservation | Zachowanie dowodu w stanie niezmienionym. |
| E-discovery | Identyfikacja i przekazywanie danych elektronicznych w kontekście prawnym. |
| Automation | Automatyczne wykonanie zadania. |
| Orchestration | Połączenie wielu automatycznych kroków w proces. |
Przykłady
Przykład 1: Podejrzane logowanie
SIEM generuje alert: konto użytkownika zalogowało się z dwóch odległych krajów w ciągu 10 minut. Analityk nie powinien od razu zakładać przejęcia konta. Powinien sprawdzić VPN, historię logowań, urządzenie, MFA, adresy IP, aktywność po logowaniu i inne alerty. Jeśli konto wykonało nietypowe działania, sprawa może zostać eskalowana do incydentu.
Przykład 2: Ransomware na endpointcie
EDR wykrywa masową zmianę plików, podejrzany proces i komunikację z nieznaną domeną. Najpierw trzeba ograniczyć skutki: izolacja hosta, sprawdzenie konta użytkownika, analiza udziałów sieciowych. Następnie usuwa się przyczynę, odtwarza dane i wykonuje RCA.
Przykład 3: Możliwa eksfiltracja danych
DLP wykrywa próbę wysłania pliku z danymi klientów na prywatny adres e-mail. Do analizy przydadzą się DLP logs, email gateway logs, endpoint logs, application logs i ewentualnie NetFlow. Celem jest ustalenie, czy dane faktycznie opuściły organizację i czy użytkownik działał przypadkowo, czy złośliwie.
Przykład 4: Dochodzenie z dowodami
Organizacja podejrzewa insider threat. Trzeba zabezpieczyć laptop, logi dostępu, logi poczty i historię pobierania plików. Jeżeli sprawa może mieć skutki prawne, należy zachować chain of custody i legal hold.
Praktyczne zastosowania
Budowanie podstawowego procesu triage alertów.
Dobieranie narzędzi do typu problemu.
Analiza logów z wielu źródeł.
Ograniczanie skutków incydentu przez izolację, blokady i segmentację.
Tworzenie timeline incydentu.
Dokumentowanie dowodów.
Automatyzowanie powtarzalnych działań SOC.
Przygotowanie do pytań performance-based dotyczących logów i reakcji.
Częste pomyłki
| Pomyłka | Dlaczego jest błędna | Poprawne rozumienie |
|---|---|---|
| „Każdy alert to incydent.” | Alert wymaga weryfikacji. | Incydent to sytuacja wymagająca reakcji po analizie. |
| „SIEM sam rozwiązuje incydenty.” | SIEM koreluje i alarmuje, ale wymaga procesu i ludzi. | SIEM wspiera SOC. |
| „EDR i SIEM to to samo.” | EDR skupia się na endpointach, SIEM koreluje wiele źródeł. | Narzędzia się uzupełniają. |
| „Containment i eradication to to samo.” | Containment ogranicza skutki, eradication usuwa przyczynę. | Kolejność działań ma znaczenie. |
| „Packet capture zawsze jest pierwszym źródłem.” | Często wystarczą logi aplikacji, endpointa, IAM lub firewall. | Źródło dobiera się do pytania. |
| „DLP robi backup danych.” | DLP wykrywa lub blokuje wypływ danych. | Backup służy odtwarzaniu. |
| „Forensics to zwykłe naprawianie systemu.” | Forensics skupia się na dowodach i ich integralności. | Nie wolno niszczyć dowodów. |
| „Automatyzacja zawsze zmniejsza ryzyko.” | Źle zaprojektowana może masowo powielać błędy. | Automatyzację trzeba testować i kontrolować. |
Typowe błędy
Brak triage alertów
Zespół reaguje chaotycznie albo ignoruje alerty bez wstępnej oceny.
Niewłaściwe źródło danych
Analityk sprawdza firewall, gdy potrzebne są logi aplikacji, albo analizuje endpoint, gdy problem jest w IAM.
Brak izolacji aktywnego zagrożenia
Podejrzany host nadal komunikuje się z siecią, bo zespół zaczyna od długiej analizy zamiast containment.
Niszczenie dowodów
Restart, kasowanie plików lub reinstalacja systemu przed zabezpieczeniem informacji może utrudnić dochodzenie.
Brak lessons learned
Incydent zostaje „zamknięty”, ale kontrola, która zawiodła, nie zostaje poprawiona.
Automatyzacja bez wyjątków i testów
Źle napisana reguła może blokować konta, usługi lub ruch produkcyjny.
Co trzeba umieć na egzamin
W tej części domeny 4.0 trzeba umieć:
- wyjaśnić monitoring, log aggregation, alerting, reporting i archiving
- wskazać, kiedy użyć SIEM, DLP, antivirus, SNMP traps, NetFlow i vulnerability scanners
- dobrać firewall rules, access lists, IDS/IPS, web filter, DNS filtering i email security
- rozumieć DMARC, DKIM i SPF jako mechanizmy bezpieczeństwa poczty
- wskazać zastosowanie FIM, DLP, NAC, EDR/XDR i UBA
- rozumieć zastosowania automatyzacji: ticket creation, escalation, disabling access, CI/testing, API integrations
- znać etapy incident response
- odróżnić containment, eradication i recovery
- wskazać legal hold, chain of custody, acquisition i preservation
- dobrać źródła danych do dochodzenia.
Checklista
User powinien umieć:
- Odróżnić event, alert i incident.
- Wyjaśnić log aggregation.
- Wyjaśnić alert tuning.
- Opisać rolę SIEM.
- Odróżnić SIEM od EDR.
- Wyjaśnić DLP, EDR, XDR, NAC, FIM i UBA.
- Odróżnić DNS filtering od web filtering.
- Wyjaśnić podstawowy sens SPF, DKIM i DMARC.
- Wyjaśnić NetFlow, SNMP traps i packet capture.
- Wymienić etapy incident response.
- Odróżnić containment, eradication i recovery.
- Wyjaśnić threat hunting.
- Wyjaśnić root cause analysis.
- Wyjaśnić legal hold i chain of custody.
- Dobrać źródło danych do pytania dochodzeniowego.
- Wskazać korzyści i ryzyka automatyzacji.
- Pytania kontrolne
- Czym różni się event od alertu?
- Kiedy alert staje się incydentem?
- Do czego służy SIEM?
- Czym różni się SIEM od EDR?
- Kiedy użyć DLP?
- Kiedy użyć FIM?
- Czym różni się DNS filtering od web filtering?
- Do czego służą SPF, DKIM i DMARC?
- Czym różni się NetFlow od packet capture?
- Jakie są główne etapy incident response?
- Czym różni się containment od eradication?
- Co oznacza recovery?
- Co to jest threat hunting?
- Co to jest root cause analysis?
- Co oznacza chain of custody?
- Po co jest legal hold?
- Jakie źródło danych wybrać do analizy podejrzanego procesu na laptopie?
- Jakie źródło danych wybrać do analizy masowego eksportu z aplikacji?
- Kiedy automatyzacja może być ryzykowna?
- Dlaczego lessons learned jest ważne?
- Odpowiedzi z wyjaśnieniami
- Event to pojedynczy fakt, alert to ostrzeżenie wygenerowane na podstawie reguły lub analizy.
- Alert staje się incydentem, gdy analiza potwierdzi lub wystarczająco uprawdopodobni naruszenie bezpieczeństwa wymagające reakcji.
- SIEM zbiera, normalizuje, koreluje i analizuje logi z wielu źródeł.
- SIEM koreluje wiele źródeł danych, a EDR skupia się na endpointach i ich zachowaniu.
- DLP stosuje się, gdy trzeba wykrywać lub blokować nieautoryzowany wypływ danych wrażliwych.
- FIM stosuje się do wykrywania zmian w ważnych plikach, np. konfiguracyjnych lub systemowych.
- DNS filtering blokuje zapytania do domen, web filtering kontroluje dostęp do stron, URL-i i kategorii treści.
- SPF, DKIM i DMARC pomagają weryfikować autentyczność poczty i ograniczać spoofing domeny.
- NetFlow pokazuje metadane przepływu, a packet capture przechwytuje szczegółowe pakiety.
- Etapy: preparation, detection, analysis, containment, eradication, recovery, lessons learned.
- Containment ogranicza skutki, eradication usuwa przyczynę.
- Recovery przywraca systemy do normalnego działania w kontrolowany sposób.
- Threat hunting to proaktywne szukanie śladów zagrożeń bez czekania na alert.
- Root cause analysis ustala przyczynę źródłową incydentu.
- Chain of custody dokumentuje, kto miał dostęp do dowodu, kiedy i co z nim zrobił.
- Legal hold nakazuje zachować dane, które mogą być istotne prawnie lub dochodzeniowo.
- Endpoint logs lub EDR telemetry.
- Mogą pokazać proces, drzewo procesów, pliki, użytkownika i połączenia.
- Application logs, DLP logs, proxy/firewall logs i endpoint logs.
- Aplikacja pokaże operację biznesową, DLP i sieć pokażą potencjalny wypływ.
- Automatyzacja jest ryzykowna, gdy działa na podstawie źle dostrojonych alertów albo może zablokować krytyczne konta i usługi bez kontroli.
- Lessons learned pozwala poprawić kontrole i procesy, aby incydent nie powtórzył się tą samą drogą.
- Zadania praktyczne
- Laboratorium 1: Triage alertu SIEM
Cel:
Przećwiczyć analizę alertu bez pochopnej klasyfikacji jako incydentu.
Kontekst:
SIEM wygenerował alert: konto jan.k zalogowało się z nietypowej lokalizacji, a 10 minut później pobrało dużą liczbę plików z aplikacji firmowej.
Kroki:
- Wypisz, jakie dane trzeba sprawdzić.
- Wskaż minimum pięć źródeł danych.
- Określ, jakie informacje potwierdzałyby incydent.
- Określ, jakie informacje mogłyby wyjaśnić aktywność jako legalną.
- Zaproponuj pierwsze działanie containment, jeśli ryzyko się potwierdzi.
Oczekiwany rezultat:
Plan triage: pytanie → źródło danych → możliwa interpretacja.
Kryteria zaliczenia:
- Uwzględniono IAM/MFA logs.
- Uwzględniono application logs.
- Uwzględniono endpoint lub EDR logs.
- Uwzględniono firewall/proxy/DLP logs.
- Nie uznano alertu automatycznie za incydent bez analizy.
- Zaproponowano containment, np. blokadę sesji lub konta, jeśli aktywność jest podejrzana.
To ćwiczenie wykonuj wyłącznie w legalnym, kontrolowanym środowisku laboratoryjnym. Nie stosuj go wobec cudzych systemów, sieci ani kont.
Laboratorium 2: Plan reakcji na ransomware
Cel:
Przećwiczyć kolejność działań incident response.
Kontekst:
Użytkownik zgłasza, że pliki na laptopie zmieniły rozszerzenia. EDR pokazuje podejrzany proces i połączenia do nieznanej domeny. Część udziałów sieciowych ma zmodyfikowane pliki.
Kroki:
- Wskaż działania preparation, które powinny istnieć przed incydentem.
- Wskaż sygnały detection.
- Wskaż, jakie dane analizować.
- Zaproponuj containment.
- Zaproponuj eradication.
- Zaproponuj recovery.
- Wypisz lessons learned.
Oczekiwany rezultat:
Plan reakcji zgodny z etapami incident response.
Kryteria zaliczenia:
- Izolowano podejrzany host.
- Sprawdzono zasięg infekcji.
- Nie rozpoczęto od kasowania dowodów.
- Uwzględniono backupy i ich bezpieczeństwo.
- Uwzględniono RCA i poprawę kontroli.
To ćwiczenie wykonuj wyłącznie w legalnym, kontrolowanym środowisku laboratoryjnym. Nie stosuj go wobec cudzych systemów, sieci ani kont.
Laboratorium 3: Dobór źródeł danych do dochodzenia
Cel:
Ćwiczyć wybór właściwych logów i źródeł danych.
Kontekst:
| Pytanie dochodzeniowe | Twoje źródła danych |
|---|---|
| Czy konto administratora było użyte poza godzinami pracy? | ? |
| Czy host wysyłał dane do nieznanego adresu IP? | ? |
| Czy aplikacja wykonała masowy eksport danych? | ? |
| Czy użytkownik próbował wysłać dane klientów e-mailem? | ? |
| Czy ktoś zmienił plik konfiguracyjny serwera? | ? |
| Czy urządzenie niezgodne z polityką podłączyło się do sieci? | ? |
Kroki:
- Dla każdego pytania wybierz minimum dwa źródła danych.
- Uzasadnij wybór.
- Wskaż, które źródło jest główne, a które pomocnicze.
- Wskaż, jak zbudować timeline.
Oczekiwany rezultat:
Tabela: pytanie → główne źródło → źródło pomocnicze → uzasadnienie.
Kryteria zaliczenia:
- Dla admina uwzględniono IAM/PAM/OS security logs.
- Dla ruchu sieciowego uwzględniono NetFlow/firewall/packet capture.
- Dla eksportu danych uwzględniono application logs.
- Dla e-maila uwzględniono DLP/email gateway.
- Dla zmiany pliku uwzględniono FIM.
- Dla urządzenia w sieci uwzględniono NAC.
To ćwiczenie wykonuj wyłącznie w legalnym, kontrolowanym środowisku laboratoryjnym. Nie stosuj go wobec cudzych systemów, sieci ani kont.
Mini-test
Pytanie 1
Co najlepiej opisuje alert?
A. Każde zdarzenie systemowe
B. Ostrzeżenie wygenerowane przez regułę, narzędzie lub korelację
C. Zawsze potwierdzony incydent
D. Fizyczny dowód w sprawie sądowej
Poprawna odpowiedź:
B
Wyjaśnienie:
Alert jest sygnałem wymagającym analizy, ale nie musi oznaczać potwierdzonego incydentu.
Dlaczego pozostałe odpowiedzi są gorsze:
- A: To event.
- C: Alert wymaga weryfikacji.
- D: To może dotyczyć forensics, ale nie alertu.
- Pytanie 2
Firma chce centralnie korelować logi z firewalli, endpointów i aplikacji. Co najlepiej pasuje?
A. SIEM
B. UPS
C. Data masking
D. Cold site
Poprawna odpowiedź:
A
Wyjaśnienie:
SIEM służy do centralizacji, korelacji i analizy zdarzeń bezpieczeństwa.
Dlaczego pozostałe odpowiedzi są gorsze:
- B: Dotyczy zasilania.
- C: Dotyczy ochrony danych w prezentacji.
- D: Dotyczy odtwarzania po awarii.
- Pytanie 3
Które narzędzie najlepiej wykryje nieautoryzowaną próbę wysłania danych klientów poza organizację?
A. DLP
B. Load balancer
C. DHCP
D. Hot site
Poprawna odpowiedź:
A
Wyjaśnienie:
DLP wykrywa lub blokuje nieautoryzowany wypływ danych.
Dlaczego pozostałe odpowiedzi są gorsze:
- B: Rozdziela ruch.
- C: Przydziela konfigurację sieciową.
- D: Dotyczy disaster recovery.
- Pytanie 4
Podejrzany komputer komunikuje się z domeną command and control. Jakie działanie najlepiej odpowiada etapowi containment?
A. Izolacja hosta
B. Lessons learned
C. Usunięcie raportu
D. Zwiększenie uprawnień użytkownika
Poprawna odpowiedź:
A
Wyjaśnienie:
Izolacja ogranicza dalszą komunikację i potencjalne rozprzestrzenianie.
Dlaczego pozostałe odpowiedzi są gorsze:
- B: To etap końcowy.
- C: Niszczy dokumentację.
- D: Zwiększa ryzyko.
- Pytanie 5
Co oznacza chain of custody?
A. Lista serwerów DNS
B. Dokumentowanie kontroli nad dowodem
C. Szyfrowanie plików backupu
D. Reguła firewalla
Poprawna odpowiedź:
B
Wyjaśnienie:
Chain of custody pokazuje, kto miał dostęp do dowodu, kiedy i co z nim zrobił.
Dlaczego pozostałe odpowiedzi są gorsze:
- A, C, D: Nie opisują dowodowej kontroli nad materiałem.
- Pytanie 6
Analityk chce sprawdzić, który host wysyłał największą ilość danych do zewnętrznego adresu IP. Co najlepiej pasuje?
A. NetFlow
B. Data masking
C. Password vaulting
D. SAML
Poprawna odpowiedź:
A
Wyjaśnienie:
NetFlow pokazuje metadane przepływów, w tym źródło, cel i wolumen danych.
Dlaczego pozostałe odpowiedzi są gorsze:
- B: Ukrywa część danych.
- C: Dotyczy PAM.
- D: Dotyczy federacyjnego logowania.
- Pytanie 7
Który etap incident response polega na usunięciu przyczyny incydentu?
A. Containment
B. Eradication
C. Detection
D. Preparation
Poprawna odpowiedź:
B
Wyjaśnienie:
Eradication usuwa przyczynę, np. malware, podatność lub złośliwe konto.
Dlaczego pozostałe odpowiedzi są gorsze:
- A: Ogranicza skutki.
- C: Wykrywa problem.
- D: Przygotowuje organizację.
- Pytanie 8
Które źródło danych jest najtrafniejsze do sprawdzenia masowego eksportu danych z aplikacji?
A. Application logs
B. UPS logs
C. Badge access logs jako jedyne źródło
D. Monitor temperatury serwerowni
Poprawna odpowiedź:
A
Wyjaśnienie:
Application logs najlepiej pokazują operacje wykonywane w aplikacji, np. eksport danych.
Dlaczego pozostałe odpowiedzi są gorsze:
- B, C, D: Mogą mieć znaczenie w innych kontekstach, ale nie są głównym źródłem dla eksportu z aplikacji.
- Pytanie 9
Czym jest threat hunting?
A. Proaktywne szukanie śladów zagrożeń
B. Usuwanie wszystkich logów
C. Fizyczne niszczenie dysków
D. Delegowana autoryzacja
Poprawna odpowiedź:
A
Wyjaśnienie:
Threat hunting polega na aktywnym szukaniu zagrożeń, często na podstawie hipotez.
Dlaczego pozostałe odpowiedzi są gorsze:
- B: Jest szkodliwe.
- C: To destruction.
- D: To OAuth.
- Pytanie 10
Firma chce automatycznie tworzyć zgłoszenia i eskalować powtarzalne alerty do właściwego zespołu. Co najlepiej pasuje?
A. Automation/orchestration
B. Data sovereignty
C. Cold site
D. Tailgating
Poprawna odpowiedź:
A
Wyjaśnienie:
Automatyzacja i orkiestracja obsługują powtarzalne kroki między systemami.
Dlaczego pozostałe odpowiedzi są gorsze:
- B: Dotyczy lokalizacji i prawa danych.
- C: Dotyczy odtwarzania.
- D: To fizyczna technika social engineering.
- Fiszki
| Przód fiszki | Tył fiszki |
|---|---|
| Event vs alert? | Event to fakt; alert to ostrzeżenie wymagające analizy. |
| Alert vs incident? | Alert to sygnał; incident to sytuacja bezpieczeństwa wymagająca reakcji. |
| Co robi SIEM? | Centralizuje, koreluje i analizuje zdarzenia z wielu źródeł. |
| SIEM vs EDR? | SIEM koreluje wiele źródeł; EDR skupia się na endpointach. |
| Co robi DLP? | Wykrywa lub blokuje nieautoryzowany wypływ danych. |
| Co robi EDR? | Monitoruje endpointy i wspiera detekcję oraz reakcję. |
| Co robi XDR? | Łączy detekcję i reakcję z wielu warstw środowiska. |
| Co robi NAC? | Kontroluje dostęp urządzeń do sieci. |
| Co robi FIM? | Wykrywa zmiany ważnych plików. |
| Co robi UBA? | Analizuje zachowanie użytkowników i odchylenia od normy. |
| DNS filtering vs web filtering? | DNS blokuje domeny; web filtering kontroluje URL-e, kategorie i reputację. |
| Co robi NetFlow? | Pokazuje metadane przepływów sieciowych. |
| NetFlow vs packet capture? | NetFlow to metadane; packet capture to szczegółowe pakiety. |
| Co to jest SNMP trap? | Powiadomienie urządzenia sieciowego o zdarzeniu. |
| Etapy incident response? | Preparation, detection, analysis, containment, eradication, recovery, lessons learned. |
| Containment vs eradication? | Containment ogranicza skutki; eradication usuwa przyczynę. |
| Co to jest recovery? | Przywrócenie systemów do działania. |
| Co to jest lessons learned? | Analiza po incydencie i poprawa kontroli. |
| Co to jest threat hunting? | Proaktywne szukanie śladów zagrożeń. |
| Co to jest RCA? | Root cause analysis, czyli analiza przyczyny źródłowej. |
| Co to jest legal hold? | Obowiązek zachowania danych jako potencjalnych dowodów. |
| Co to jest chain of custody? | Dokumentacja kontroli nad dowodem. |
| Co to jest acquisition? | Pozyskanie dowodu cyfrowego. |
| Co to jest preservation? | Zachowanie dowodu w stanie niezmienionym. |
| Automation vs orchestration? | Automation wykonuje zadanie; orchestration łączy wiele kroków w proces. |
Obrazy do wygenerowania
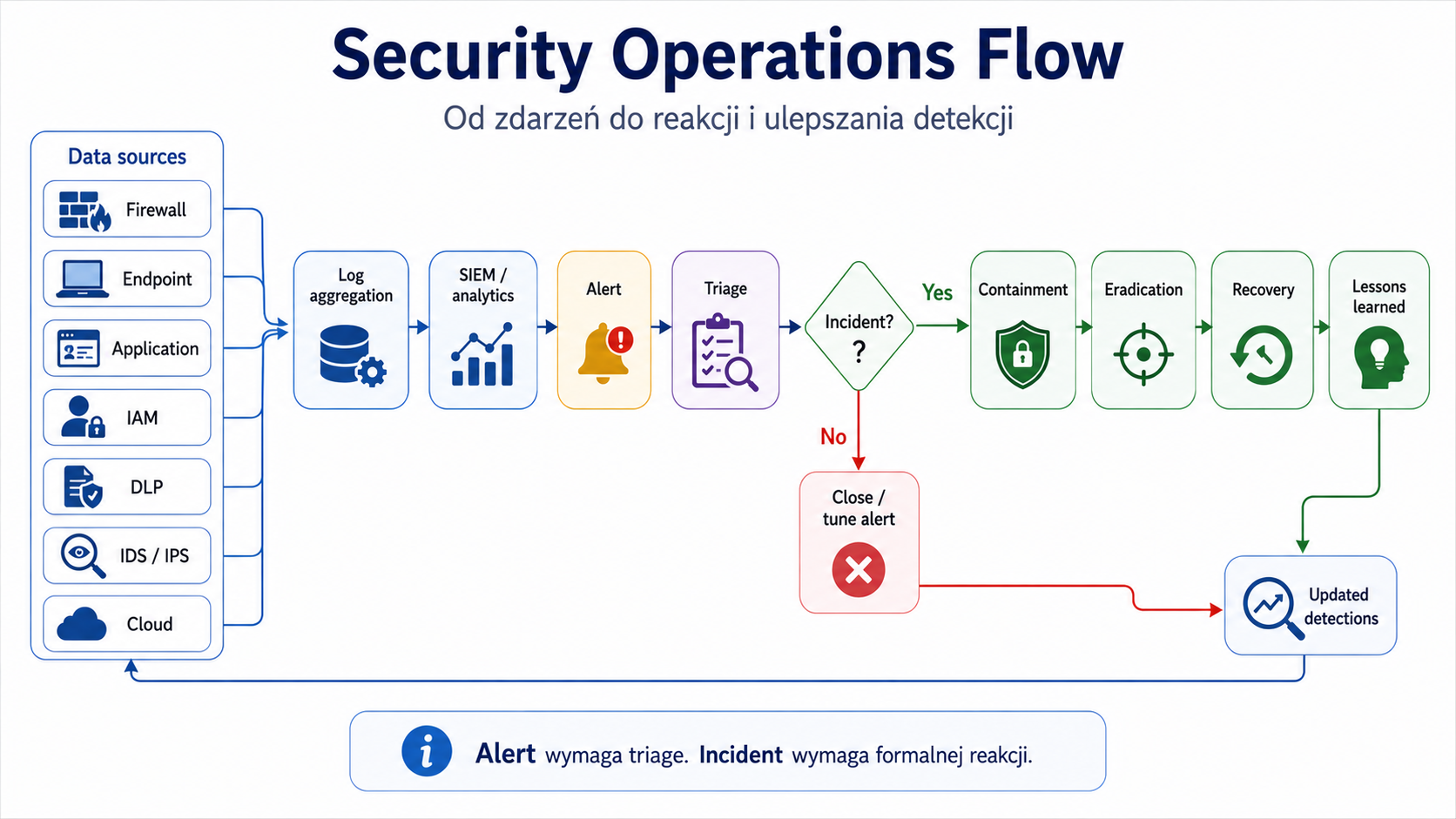
IMG_M05_S01_SECURITY_OPERATIONS_FLOW
Miejsce w materiale:
Sekcja „Wprowadzenie”.
Cel obrazu:
Pokazać ogólny przepływ pracy Security Operations.
Opis obrazu do wygenerowania:
Diagram przepływu: data sources → log aggregation → SIEM/analytics → alert → triage → incident? → containment → eradication → recovery → lessons learned → updated detections. Dodaj boczne źródła: firewall, endpoint, application, IAM, DLP, IDS/IPS, cloud.
Styl:
Schemat blokowy techniczny.
Elementy obowiązkowe:
- data sources
- log aggregation
- SIEM
- alert
- triage
- incident decision
- containment
- eradication
- recovery
- lessons learned
- updated detections.
Elementy, których unikać:
- kodu exploitów
- instrukcji ofensywnych
- nadmiaru tekstu
- symboli „hakera” bez wartości edukacyjnej.
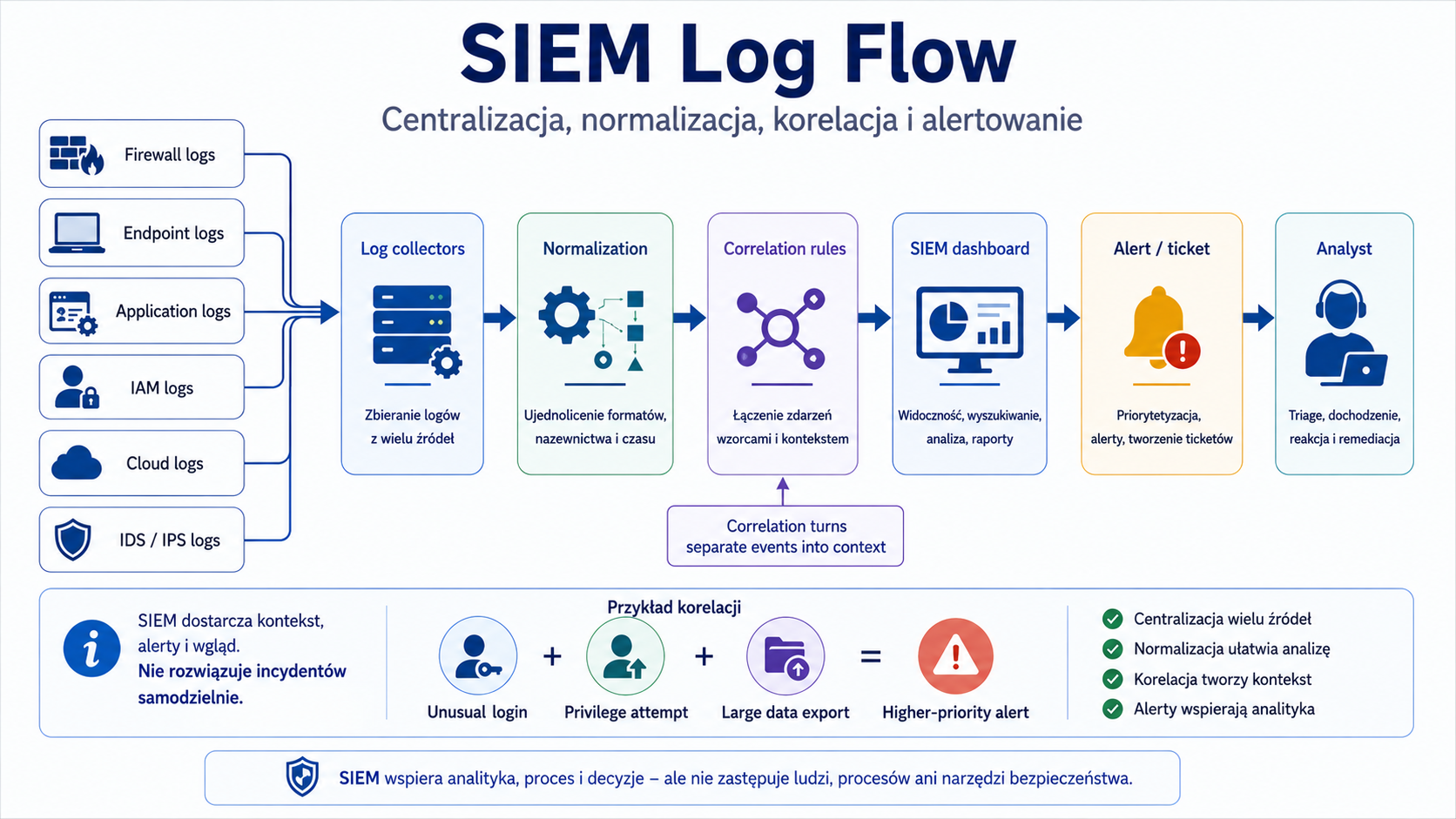
- IMG_M05_S02_SIEM_LOG_FLOW
Miejsce w materiale:
Sekcja „SIEM”.
Cel obrazu:
Wyjaśnić, skąd SIEM bierze dane i jak tworzy alert.
Opis obrazu do wygenerowania:
Diagram: firewall logs, endpoint logs, application logs, IAM logs, cloud logs, IDS/IPS logs → log collectors → normalization → correlation rules → SIEM dashboard → alert/ticket → analyst. Dodaj małą etykietę: „correlation turns separate events into context”.
Styl:
Diagram architektury monitoringu.
Elementy obowiązkowe:
- firewall logs
- endpoint logs
- application logs
- IAM logs
- cloud logs
- IDS/IPS logs
- collectors
- normalization
- correlation
- alert
- analyst.
Elementy, których unikać:
- vendor-specific nazw
- zbyt małych logów
- nadmiaru ikon.
- IMG_M05_S03_INCIDENT_RESPONSE_LIFECYCLE
Miejsce w materiale:
Sekcja „Incident response”.
Cel obrazu:
Pokazać etapy incident response i ich kolejność.
Opis obrazu do wygenerowania:
Cykliczny diagram: preparation → detection → analysis → containment → eradication → recovery → lessons learned → preparation. Przy containment dodaj przykłady: isolate host, disable account, block indicator. Przy lessons learned dodaj: improve controls, update playbook, tune alerts.
Styl:
Schemat cyklu procesu.
Elementy obowiązkowe:
- preparation
- detection
- analysis
- containment
- eradication
- recovery
- lessons learned
- przykłady działań containment
- poprawa playbooków.
Elementy, których unikać:
- zbyt długich opisów
- ofensywnych szczegółów
- chaosu wizualnego.
- IMG_M05_S04_INVESTIGATION_DATA_SOURCES
Miejsce w materiale:
Sekcja „Źródła danych w dochodzeniu”.
Cel obrazu:
Pomóc dobrać źródło danych do pytania dochodzeniowego.
Opis obrazu do wygenerowania:
Macierz: pytanie dochodzeniowe vs źródło danych. Wiersze: account activity, endpoint process, network traffic, data exfiltration, application action, file modification. Kolumny: IAM logs, EDR logs, firewall/NetFlow, DLP/email logs, application logs, FIM. W komórkach zaznacz najlepsze źródła.
Styl:
Tabela wizualna / infografika.
Elementy obowiązkowe:
- IAM logs
- EDR logs
- firewall logs
- NetFlow
- DLP/email logs
- application logs
- FIM
- packet capture
- investigative questions.
Elementy, których unikać:
- zbyt wielu szczegółów
- realnych danych użytkowników
- kodu lub payloadów.
- IMG_M05_S05_FORENSICS_CHAIN_OF_CUSTODY
Miejsce w materiale:
Sekcja „Digital forensics, legal hold i chain of custody”.
Cel obrazu:
Wyjaśnić, jak dokumentuje się dowód cyfrowy.
Opis obrazu do wygenerowania:
Diagram procesu: identify evidence → legal hold → acquire image/log export → hash/verify → store securely → document transfer → analyze copy → report. Dodaj formularz chain of custody z polami: evidence ID, date/time, handler, action, signature.
Styl:
Schemat procesu śledczego / infografika.
Elementy obowiązkowe:
- identify evidence
- legal hold
- acquisition
- hash/verify
- secure storage
- transfer documentation
- analyze copy
- report
- chain of custody form fields.
Elementy, których unikać:
- realistycznych danych osobowych
- instrukcji obchodzenia zabezpieczeń
- nieczytelnego tekstu.
- Pokrycie wymagań egzaminacyjnych
| Wymaganie egzaminacyjne SY0-701 | Gdzie jest omówione | Poziom pokrycia | Uwagi |
|---|---|---|---|
| 4.4 Explain security alerting and monitoring concepts and tools | Monitoring i alerting; SIEM; narzędzia operacyjne | Pełny | Uwzględniono log aggregation, alerting, scanning, reporting, archiving, alert tuning, SIEM, DLP, SNMP traps, NetFlow i vulnerability scanners. |
| 4.5 Given a scenario, modify enterprise capabilities to enhance security | Firewall, IDS/IPS, web filtering, DNS filtering, email security, FIM, DLP, NAC, EDR/XDR, UBA | Pełny | Uwzględniono dobór kontroli do scenariuszy i różnice między narzędziami. |
| 4.7 Explain the importance of automation and orchestration related to secure operations | Automatyzacja i orkiestracja | Pełny | Uwzględniono use cases, korzyści i ryzyka automatyzacji. |
| 4.8 Explain appropriate incident response activities | Incident response; threat hunting; RCA | Pełny | Uwzględniono cały cykl IR, tabletop/simulation jako kontekst testowania oraz RCA. |
| 4.9 Given a scenario, use data sources to support an investigation | Źródła danych w dochodzeniu; forensics | Pełny | Uwzględniono firewall, application, endpoint, OS security, IDS/IPS, network logs, metadata, vulnerability scans, dashboards i packet captures. |
Co warto powtórzyć przed przejściem dalej
Event vs alert vs incident.
SIEM vs EDR vs XDR.
DLP, NAC, FIM, UBA.
IDS vs IPS.
DNS filtering vs web filtering.
SPF, DKIM, DMARC.
NetFlow vs packet capture.
Etapy incident response.
Containment vs eradication vs recovery.
Threat hunting vs alert response.
RCA.
Legal hold i chain of custody.
Dobór źródła danych do pytania dochodzeniowego.
Automation vs orchestration.
Kontrola kompletności modułu
Zakres z konspektu pokryty:
- monitoring systemów, aplikacji i infrastruktury
- log aggregation, alerting, scanning, reporting, archiving, alert response, alert tuning
- SIEM, DLP, antivirus jako kategoria narzędzia, SNMP traps, NetFlow, vulnerability scanners
- firewall, IDS/IPS, web filter, DNS filtering, email security, FIM, DLP, NAC, EDR/XDR, UBA
- automatyzacja i orkiestracja
- incident response
- threat hunting
- root cause analysis
- digital forensics
- legal hold, chain of custody, acquisition, preservation, reporting, e-discovery
- log data i data sources
- ćwiczenia, mini-test, fiszki, obrazy i kontrola pokrycia wymagań.
Zakres wymagający pogłębienia:
- formalne playbooki, polityki incident response i governance wrócą w module 6.
- risk management i business impact analysis wrócą w module 6.
- dodatkowy trening pytań scenariuszowych i PBQ będzie w module 7.
- szczegółowe narzędzia konkretnych producentów nie są potrzebne na poziomie Security+.
Najważniejsze rzeczy do zapamiętania:
- Alert wymaga triage, a nie automatycznego uznania za incydent.
- SIEM pomaga korelować dane, ale wymaga dobrych źródeł i procesu.
- Narzędzie dobiera się do problemu: dane, endpoint, sieć, aplikacja, użytkownik, pliki.
- Incident response ma kolejność: preparation, detection, analysis, containment, eradication, recovery, lessons learned.
- Nie niszcz dowodów przed analizą i zabezpieczeniem.
- Chain of custody jest kluczowe, gdy dowody mogą mieć znaczenie prawne.
- Automatyzacja przyspiesza reakcję, ale musi być testowana i kontrolowana.
Czy materiał wystarcza do opanowania tej części:
Tak, jako pełne wprowadzenie do monitoringu, detekcji, incident response, forensics i źródeł danych na poziomie Security+ SY0-701.
Potencjalne luki:
- Warto później zrobić osobny zestaw ćwiczeń z interpretacji logów.
- Warto po module 6 wrócić do incident response jako elementu polityk, procedur i governance.
- Warto w module 7 przećwiczyć PBQ polegające na dopasowywaniu źródeł danych do scenariusza.
Rekomendowana powtórka:
- Przerób fiszki.
- Rozwiąż mini-test bez patrzenia w odpowiedzi.
- Wykonaj laboratorium 1 i 2.
- Dla każdego scenariusza zapisuj: źródła danych → hipoteza → analiza → containment → eradication → recovery → lessons learned.
- Narysuj prosty przepływ: logi → SIEM → alert → triage → incident response.
- Kontrola głębokości wyjaśnień
- Ważne pojęcia zostały rozwinięte, a nie tylko wymienione.
- Przy każdym kluczowym obszarze pokazano problem, mechanizm, przykład praktyczny, scenariusz egzaminacyjny, częste pomyłki i definicję.
- Dodano ćwiczenia, checklistę, pytania kontrolne, odpowiedzi, mini-test, fiszki i opisy obrazów.
- Ćwiczenia są defensywne i przeznaczone wyłącznie do legalnego, kontrolowanego środowiska.
- Struktura odpowiada wymaganiom generowania właściwego materiału szkoleniowego.